Search
ICNAP is a collaborative center where we come together to address and solve the challenges of digitalization
66
Projects
15
Services
49
Files
7
Topic Fields
70
Scientific Contributors
4
Institutes
To fully leverage the benefits of our resources, we invite you to become a member of our community. Membership provides you with exclusive access to all project results, allowing you to delve deeper into the world of ICNAP.
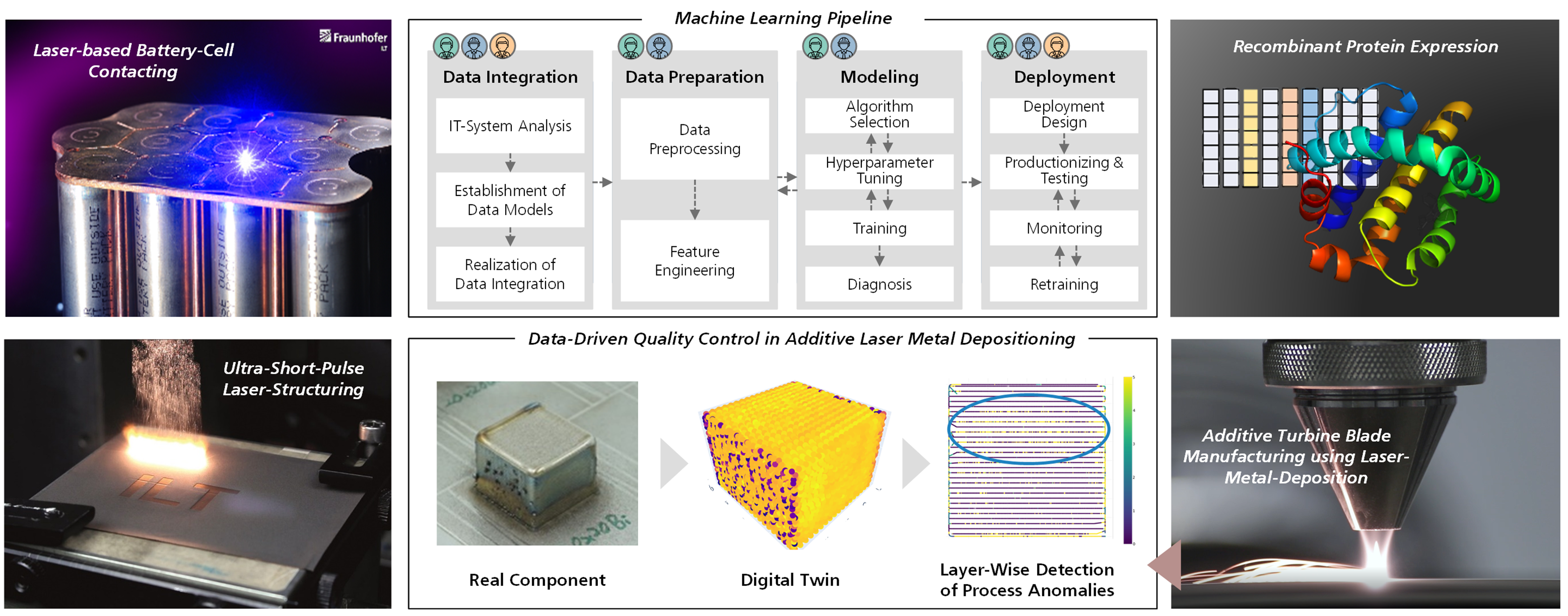
Data-driven modeling with machine learning algorithms allows for the extraction of knowledge and identification of features in complex data sets.
| Topic Fields | |
| Published | 2021 |
| Involved Institutes | |
| Project Type | ICNAP Research/Transfer Project |
| Responsibles |
Contact us to get in touch! With a membership, you’ll gain full access to all project information and updates.
Data-driven modelling utilizing machine learning (ML) algorithms facilitates the extraction of knowledge and the identification of process characteristics from high- dimensional data. In this project, we investigated on four different use-cases, how ML can enhance process development and quality control in manufacturing. For this, data- driven process models were developed for (1) laser beam welding in battery cell contacting, (2) ultra-short-pulse laser structuring of metallic surfaces, (3) 3D-printing of turbine blades using laser metal deposition, and (4) recombinant protein expression. According to each process, supervised or unsupervised ML models were trained and analyzed based on process parameters, process monitoring data and quality measures.
Our results demonstrate the enormous potential of ML-based data processing for quality, efficiency, and sustainability enhancement. The developed data models allow not only to predict and to control the final product qualities, but also to identify the sequence of influence of process parameters on the outcome. Our research further shows that in real- world applications, data quality is paramount to the performance of the models. Data quality proved to be more important than its mere quantity. The future design or retrofitting of processes should therefore aim for achieving a highest possible data quality. Analyzing and processing these high-dimensional and large datasets places utmost demands on computational infrastructure and resources. Furthermore, for feeding gained insights back into process development, but also for relying on the models during operation, it is decisive that the model functionalities and their predictions must be transparent and comprehensible for both the process experts and operators. The optimization of data quality, model performances and also the explainability of ML will be the focus of our future work in order to achieve a benefit-maximizing, area-wide use of trustworthy ML models in a variety of production domains.
© Fraunhofer 2025





